

どうやってやればいいんだろう。。
CSVデータに出力したいんだけど。。
こんにちは、古賀です!
本記事は、
はてな
「Python機械学習でホームラン数を予測する」のデータ収集「WEBスクレイピング」編
です!
機械学習をするには、まず「データ」が必要です!
今回は「2020年のプロ野球データ」を、
「WEBスクレイピング」という方法を使って「データ収集」を行い、
それをCSVファイルに出力します!
「機械学習の導入部分」
「WEBスクレイピングの基本」
を学びましょう!
前回の続きになりますので、
前回の記事を読まれていない方はまずはこちらをご覧ください!
-

-
Python機械学習「ホームラン数予測①」概要編!
PythonってAIや機械学習ができるって言うけど、 誰にでもできるんだろうか。。 やっぱり難しいコードを書いたりするんだろうか。。 イメージを掴みたいな。。 こんにちは、 ...
続きを見る
また、実行環境は「JupyterLab」を使っていきますので、
「JupyterLab」の記事を読まれていない方は、こちらもご確認ください!
-

-
JupyterLabとは?Python実行環境「JupyterLab」の概要と基本的な使い方!
Pythonの実行環境「JupyterLab」が起動できるところまできたけど、 どういう風に使っていけばいいんだろう?? そもそも「JupyterLab」ってなんだ?? こ ...
続きを見る
自己紹介が遅れましたが、
わたしは大学卒業後、上場IT企業に就職し、プログラマー、システムエンジニアとして
約10年間働いておりまして、その後は様々な活動をしております。
プロフィールの詳細はこちらです。
-

-
プロフィール
こんにちは、古賀正雄です。 簡単ではありますが、こちらのページで自己紹介とこのブログについてお話します。 高校時代 学生時代は主に野球をしていました。 進学先の高校も野球で選びました。 ...
続きを見る
※YouTubeに同内容を公開しております。
Python機械学習「WEBスクレイピング」の概要

機械学習をするためには、まず「データ」が必要です。
そのデータを今回は、
WEBサイトから情報を取ってくる「WEBスクレイピング」
という方法で取ってきます。
WEBサイトは、「プロ野球データFREAK」様のサイトのこのページをお借りしたいと思います。
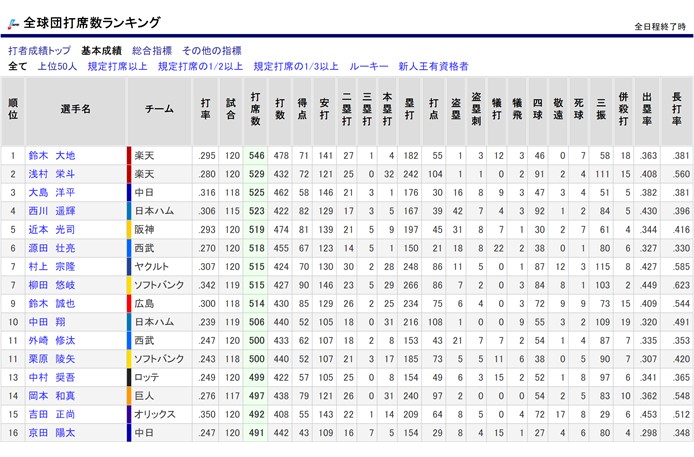
この表形式で表示されているデータを、CSVファイルに出力することが今回のゴールです!
手順としては、
- プロ野球データが表示されているURLにアクセス
- HTMLデータを取得
- HTMLデータから各項目の値を取得し、配列変数にセット
- 配列変数を表形式データに変換
- 表形式データをCSVファイルに出力
です!
Python機械学習「WEBスクレイピング」をしてみる!

今回のコード全体です。
今からこのコードを1から説明していきます!
#WEB上のデータ(HTML)にアクセス&取得するために使用
import urllib
#HTMLからデータを抽出するために使用
from bs4 import BeautifulSoup
#表形式でデータ格納するために使用
import pandas as pd
url = 'https://baseball-data.com/stats/hitter2-all/tpa-1.html'
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
#HTMLから表(tableタグ)の部分を全て取得する
table = soup.find_all('table')[0]
#テーブルから行データを取得
rows = table.find_all('tr')
#データ格納用
headData = []
playerData = []
for i, row in enumerate(rows):
#1行目
if i == 0:
#ヘッダ部取得
for headerValue in row.find_all('th'):
headData.append(headerValue.get_text())
#2行目~最終行未満
elif (i > 0) and (i + 1 < len(rows)):
#明細部取得
playerRow = []
for playerValue in row.find_all('td'):
playerRow.append(playerValue.get_text())
playerData.append(playerRow)
#DataFrameに変換
df = pd.DataFrame(data = playerData, columns = headData)
#CSV出力
df.to_csv('playerData.csv', sep = ',', header = True, index = False)
WEBスクレイピングで使用するライブラリを宣言
はじめに「WEBスクレイピング」をするために使用するライブラリを宣言します。
※ライブラリをモジュールと呼んだりもしますが、「ライブラリ」で統一します。
#WEB上のデータ(HTML)にアクセス&取得するために使用 import urllib #HTMLからデータを抽出するために使用 from bs4 import BeautifulSoup #表形式でデータ格納するために使用 import pandas as pd
Pythonでは「import ライブラリ名」とすることで、ライブラリを使えるようになります。
「from ライブラリ名 import クラス名など」という書き方でライブラリ全体ではなく、
そのライブラリの一部分だけ使えるようにすることもできます。
また「as 名前」とすることで、別名を付けることもできます。
今回は、
- WEB上のデータ(HTML)にアクセス&取得するために使用する「urllib」
- HTMLからデータを抽出するために使用する「BeautifulSoup」
- 表形式でデータ格納するために使用する「Pandas」
を宣言しておきます。
WEBサイトからHTMLデータの取得
次に、WEBサイトからHTMLデータを取得していきます。
難しいことは何もありません。
先程宣言したライブラリ「urllib」と「BeautifulSoup」を使うだけです。
url = 'https://baseball-data.com/stats/hitter2-all/tpa-1.html' html = urllib.request.urlopen(url) soup = BeautifulSoup(html, 'html.parser')
1行目は、変数に「取ってきたいデータが表示されているサイトのURL」をセットしています。
変数の説明はいらないと思いますが、変数は値を格納しておくためのものです。
ちなみにPythonでは「str url」というように、変数の前にデータ型の宣言を書く必要はありません。
「この変数は型は何だっけ?」
となりがちなので、「type(変数)」を使うことで確認できるので覚えておきましょう!
print(type(url)) <class 'str'>
「<class 'str'>」と表示され、文字型だということが確認できます。
2行目は、そのURLの変数を「urllibのHTMLデータを取得する関数」に渡して、
「html」という変数にセットしています。
※もちろん変数を使わず、関数に直接WEBサイトのURLを渡しても問題なしです。
3行目は、取得してきたHTMLデータを「BeautifulSoup」を使って、
HTMLデータから値を取得できるように変換を行っています。
いまいちピンとこないかもしれませんが、2~3行目は決まり事のような感じなので、
HTMLから値を取ってくる前の下準備と思っておいてください。
これでHTMLデータが取得できました!
表形式HTMLデータの構造
実際に手を動かす前に、データが表形式で表示されている「HTML」の構造を確認しておきましょう。
プロ野球データのサイトで「右クリック⇒検証」を押して、
「デベロッパーツール」を立ち上げます。
これでWEBサイトの「HTML」を確認できるのですが、
見て欲しいところが、今回データ取得対象である表形式となっている部分です。
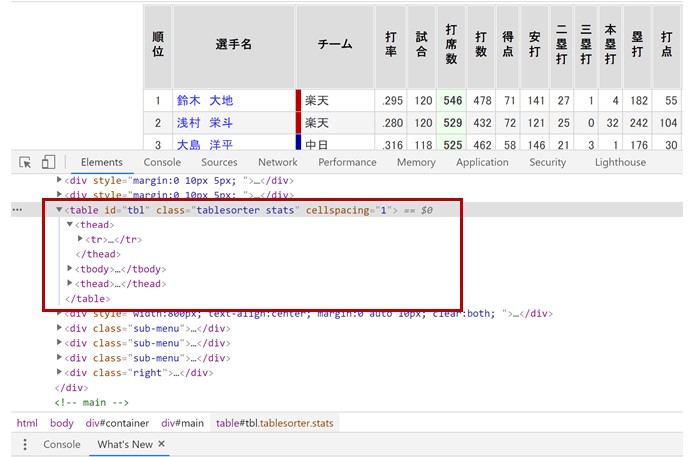
表形式となっているところが、
「table」や「thead」、「tbody」、「tr」という「タグ」が見えると思います。
HTMLの構造を簡略化して書くと、下のような構造になっています。
<table>
<thead>
<tr>
<th>
選手名
</th>
<th>
チーム
</th>
・・・・・略・・・・
</tr>
</thead>
<tbody>
<tr>
<td>
鈴木 大地
</td>
<td>
楽天
</td>
・・・・・略・・・・
</tr>
<tr>
<td>
浅村 栄斗
</td>
<td>
楽天
</td>
・・・・・略・・・・
</tr>
・・・・・略・・・・
</tbody>
<thead>
↑のtheadと同様
・・・・・略・・・・
</thead>
</table>
頭に入れておいて欲しいことが、
- 表形式の部分は<table>タグで全体を囲っている
- 1行は<tr>タグで行全体を囲っている
- ヘッダの値は<th>タグで値を囲っている
- 明細の値は<td>タグで値を囲っている
この4つです。
<thead>と<tbody>は今回は使わないので、無視して大丈夫です。
これを踏まえて、続きのコードを書いていきます!
HTMLデータから値を取得
先程取得してきたHTMLデータから、表形式のデータを取り出していきます。
#HTMLから表(tableタグ)の部分を全て取得する
table = soup.find_all('table')[0]
#テーブルから行データを取得
rows = table.find_all('tr')
1行にまとめて書いても良いのですが、説明のためと、理解しやすいように2行で書いています。
1行目で先程取得してきたHTMLデータに対して、「find_all」関数を使っています。
「find_all」関数の引数に「'table'」を指定していますが、
これで「tableタグで囲われたデータを取ってきてください!」という意味になります。
そして最後に[0]を付けていますが、「soup.find_all('table')」だけだと「配列型」で値が返ってきます。
配列についても、簡単に説明しておきます。
先程変数について説明しましたが、配列型でない普通の変数は1つの値しか格納できません。
それに対して配列型だと、複数の値を格納することができます。
普通の変数が1件家なら、配列はマンションのような感じです。
以下が例です。
normal = 'a' hairetu = ['a', 'b', 'c'] print(normal) print(hairetu[0]) print(hairetu[1]) print(hairetu[2]) #実行結果 a a b c
なので先程の[0]は、配列型で格納されているtableデータの1つ目という意味です。
※配列は0から始まるので注意です。
今回のWEBサイトは表形式のデータが1つしかないので、
配列型でデータが返ってきても結局1つなのですが、
もし表形式が複数あったら、取得したい方の配列番号を指定する必要があります。
そして2行目でtableデータに対して「find_all」関数を使って、
「trタグ」で囲われたデータを取ってきています。
今度は[0]を付けていないので、配列型として「rows」に格納しています。
次の処理に入る前に、配列型の変数を2つ宣言しておきます。
#データ格納用 headData = [] playerData = []
今からデータの値を取得してきますが、その値の格納する配列型変数です。
イメージとしては、
headData = ['選手名', 'チーム'・・・] playerData = [['鈴木 大地', '楽天'・・・] , ['浅村 栄斗', '楽天'・・・] , [・・・] ]
となるように値をセットしていきます。
選手データは配列の中に配列があるので、少しややこしいかもしれませんが、
続きの処理を見るとなんとなく理解できると思うので、先に進みます!
それでは、行データから値を取り出していきます。
for i, row in enumerate(rows):
#1行目
if i == 0:
#ヘッダ部取得
for headerValue in row.find_all('th'):
headData.append(headerValue.get_text())
#2行目~最終行未満
elif (i > 0) and (i + 1 < len(rows)):
#明細部取得
playerRow = []
for playerValue in row.find_all('td'):
playerRow.append(playerValue.get_text())
playerData.append(playerRow)
ちょっと盛沢山になってきましたが、1つずつ説明していきます。
まず「for」文です。
プログラミング経験者なら知っていると思いますが、
「for文は繰り返し処理」です。
「for 変数 in 配列型」と書くことで、配列の中身が一つずつ変数に格納され、
配列の中身がなくなるまで、繰り返し処理を行います。
※ちなみにPythonでは{}やBEGIN、ENDで処理をくくるのではなく、
インデントで処理の範囲が判断されます。
簡単な例だと、このようになります。
for i in ['a','b','c']:
print(i)
#結果
a
b
c
ただし今回の場合は、
「for 変数1, 変数2 in enumerate(配列型)」
という書き方になっています。
「enumerate」
を使うことで、「変数1」に配列番号が入り、「変数2」に配列の値が入ります。
配列番号と言うより、行番号と言った方が分かりやすいかもしれません。(0始まりですが)
今回は表形式データの行番号も欲しかったので、このような書き方になりました。
ループ処理の中身に入りますが、今度は「if」文です。
こちらもプログラミング経験者なら当たり前の処理ですが、
if 条件文:
条件を満たすと処理実行
elif 条件文:
ifの条件を満たさないかつ、elif条件を満たすと処理実行
else:
上記の条件をどれも満たさないと処理実行
というやつです。
そのif文の条件に「i == 0」としています。
※「==」で「等しい」という意味です。「=」だと「代入」という意味になります。
#1行目
if i == 0:
#ヘッダ部取得
for headerValue in row.find_all('th'):
headData.append(headerValue.get_text())
「for文」の説明の時に「enumerate」を使うことで、
「変数1」である「i」に「行番号」がセットされると説明しました。
なので「i == 0」で、「先頭行だったら」ということになります。
1回目のループでしたいことは、
データの項目名「選手名」、「チーム」という部分の取得です。
それを「for文」で処理しています。
行データからヘッダの値がセットされている「thタグ」を取得して、1つずつ処理しています。
「thデータ」に対して「get_text()」を使う事で値を取り出すことができます。
それをヘッダ部格納用配列変数「headData」に「append」をしています。
「append」は配列要素の追加です。
for文が処理されるごとに、「選手名」、「チーム」、「打率」という項目名がセットされていきます。
取得してきた結果を確認すると、こんな感じです。
print(headData) 結果 ['順位', '選手名', 'チーム', '打率', '試合', '打席数', '打数', '得点', '安打', '二塁打', '三塁打', '本塁打', '塁打', '打点', '盗塁', '盗塁刺', '犠打', '犠飛', '四球', '敬遠', '死球', '三振', '併殺打', '出塁率', '長打率']
これで目的の1つ、ヘッダの項目名を取ってこれました!
続いて選手データ部分ですが、for文の中の2つ目の「elif文」が、
#2行目~最終行未満
elif (i > 0) and (i + 1 < len(rows)):
#明細部取得
playerRow = []
for playerValue in row.find_all('td'):
playerRow.append(playerValue.get_text())
playerData.append(playerRow)
このようになっています。
条件文に「and」を付けると、「両方の条件を満たしたときだけ」処理を実行するようになります。
※「どちらか一方」は「or」です。
1つ目の条件「i > 0」は「i」にループ回数が入っているので、
「行データの2行目以降」という条件になります。
2つ目の条件「i + 1 < len(rows)」は「最終行未満」という条件です。
「len」を使うと配列の「要素数」、つまり「データの行数」を取得することができます。
最終行の処理だと「行番号」=「データの行数」となるので、
「i + 1 < len(rows)」とすることで「最終行未満」とすることができます。
※「+1」は「i」が「0」から始まるためです。
なぜ最終行を省いているかと言うと、
WEBサイトを見てみると、最終行にまた「項目名」の行があるからですね。
これを省きたいがために「i + 1 < len(rows)」の条件を追加しています。
後の処理はヘッダの項目名取得と同じです。
空の配列変数「playerRow」を宣言してますが、これに先程と同様に「for文」で値を取ってきます。
明細データの値は「tdタグ」で囲ってるので、「tdタグ」を指定して値を取得します。
「playerRow」に「鈴木 大地」、「楽天」、・・・とセットされるので、
その処理が終わった後に、明細データ格納用配列変数「playerData」に追加します。
そして次のfor文の処理に移っていくと、最終的に「playerData」には、
print(playerData) 結果 [['1', '鈴木\u3000大地', '楽天', '.295', '120', '546', '478', '71', '141', '27', '1', '4', '182', '55', '1', '3', '12', '3', '46', '0', '7', '58', '18', '.363', '.381'], ['2', '浅村\u3000栄斗', '楽天', '.280', '120', '529', '432', '72', '121', '25', '0', '32', '242', '104', '1', '1', '0', '2', '91', '2', '4', '111', '15', '.408', '.560'], ['3', '大島\u3000洋平', '中日', '.316', '118', '525', '462', '58', '146', '21', '3', '1', '176', '30', '16', '8', '9', '3', '47', '3', '4', '51', '5', '.382', '.381'],
このように欲しいデータがセットされています。
これで後は表形式データに変換して、CSV出力するだけです!
配列変数を表形式データに変換
「ヘッダ項目名の配列」と、「選手データの配列」を取得できましたが、
これを表形式データに変換します!
#DataFrameに変換 df = pd.DataFrame(data = playerData, columns = headData)
これで表形式に変換できます。
表形式データをPythonで扱うためには、最初に宣言したライブラリ「Pandas」を使います。
そして、その表形式データのことを「DataFrame」と言います。
「data」の引数に「選手データの配列」、「columns」の引数に「ヘッダ項目名の配列」を渡します。
その結果を「df」変数にセットしています。
結果を確認してみると、
print(df)
結果
順位 選手名 チーム 打率 試合 打席数 打数 得点 安打 二塁打 ... 盗塁刺 犠打 犠飛 四球 \
0 1 鈴木 大地 楽天 .295 120 546 478 71 141 27 ... 3 12 3 46
1 2 浅村 栄斗 楽天 .280 120 529 432 72 121 25 ... 1 0 2 91
2 3 大島 洋平 中日 .316 118 525 462 58 146 21 ... 8 9 3 47
3 4 西川 遥輝 日本ハム .306 115 523 422 82 129 17 ... 7 4 3 92
4 5 近本 光司 阪神 .293 120 519 474 81 139 21 ... 8 7 1 30
.. ... ... ... ... ... ... ... .. ... .. ... .. .. .. ..
324 322 吉田 裕太 ロッテ .000 1 1 0 0 0 0 ... 0 1 0 0
325 322 細川 亨 ロッテ .000 1 1 1 0 0 0 ... 0 0 0 0
326 322 加藤 脩平 巨人 .000 1 1 1 0 0 0 ... 0 0 0 0
327 328 白崎 浩之 オリックス .000 3 0 0 1 0 0 ... 0 0 0 0
328 328 細谷 圭 ロッテ .000 1 0 0 0 0 0 ... 0 0 0 0
敬遠 死球 三振 併殺打 出塁率 長打率
0 0 7 58 18 .363 .381
1 2 4 111 15 .408 .560
2 3 4 51 5 .382 .381
3 1 2 84 5 .430 .396
4 2 7 61 4 .344 .416
.. .. .. ... .. ... ...
324 0 0 0 0 .000 .000
325 0 0 1 0 .000 .000
326 0 0 1 0 .000 .000
327 0 0 0 0 .000 .000
328 0 0 0 0 .000 .000
良い感じです!
表形式データをCSVファイルに出力
最後にCSVファイルに出力します。
PythonでCSVファイルを出力方法はいくつかありますが、
今回は「pandas」を使ったCSVファイルの出力です。
#CSV出力
df.to_csv('playerData.csv', sep = ',', header = True, index = False)
DataFrame変数「df」に対して「to_csv」を使うことでCSV出力ができます。
引数は順番に、
「ファイル名」、
「区切り文字」今回はCSVなのでカンマを指定してます、
「ヘッダの項目名を付けるか?」付けます、
「一番左の列に連番を付けるか?」特に使う予定はないので、付けません。
実行して出力したファイルを見てみましょう!
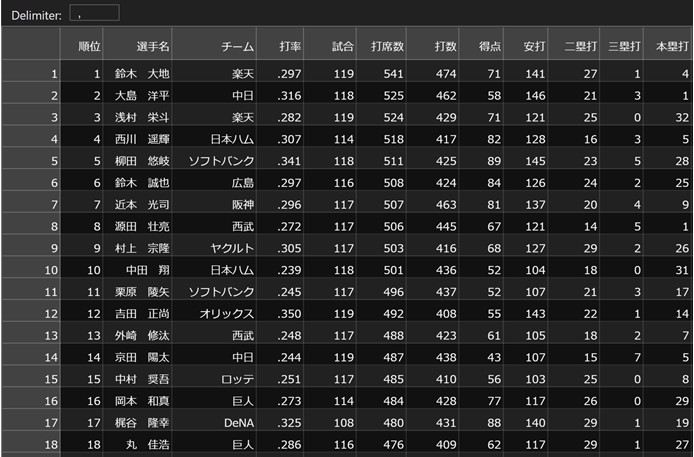
ちゃんとできています!
これで今回のやりたいことは完了です!
全体をもう一度見てみましょう!
#WEB上のデータ(HTML)にアクセス&取得するために使用
import urllib
#HTMLからデータを抽出するために使用
from bs4 import BeautifulSoup
#表形式でデータ格納するために使用
import pandas as pd
url = 'https://baseball-data.com/stats/hitter2-all/tpa-1.html'
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
#HTMLから表(tableタグ)の部分を全て取得する
table = soup.find_all('table')[0]
#テーブルから行データを取得
rows = table.find_all('tr')
#データ格納用
headData = []
playerData = []
for i, row in enumerate(rows):
#1行目
if i == 0:
#ヘッダ部取得
for headerValue in row.find_all('th'):
headData.append(headerValue.get_text())
#2行目~最終行未満
elif (i > 0) and (i + 1 < len(rows)):
#明細部取得
playerRow = []
for playerValue in row.find_all('td'):
playerRow.append(playerValue.get_text())
playerData.append(playerRow)
#DataFrameに変換
df = pd.DataFrame(data = playerData, columns = headData)
#CSV出力
df.to_csv('playerData.csv', sep = ',', header = True, index = False)
まとめ:Python機械学習「WEBスクレイピング」
ここまでの話をまとめます。
まとめ
WEBサイトから情報を取ってくる「WEBスクレイピング」と言い、
今回やったことは、
- 「urllib」を使って、プロ野球データが表示されているURLにアクセス
- 「urllib」を使って、HTMLデータを取得
- 「BeautifulSoup」を使って、HTMLデータから各項目の値を取得し、配列変数にセット
その中で繰り返し処理の「for文」、条件分岐の「if文」を使用した - 「Pandas」を使って、配列変数を表形式データに変換
- 表形式データをCSVファイルに出力
2020年のプロ野球選手データを取得することができた!
今回のWEBスクレイピングは表形式となっている部分を取得してきましたが、
表形式でなくてもWEBサイトの情報は取ってこれます。
今回は単純な例でしたが、
WEBサイトのHTML構造を分析して、
うまく「タグ」を指定したり、
今回はやりませんでしたが「クラス名」を指定したりして、
欲しい情報を取ってくるようになりましょう!
うまく使いこなせば、
これだけで仕事を受けることができますし、
仕事の手作業を減らせることができるかもしれません。
また今回の処理で、
プログラミングの基本である「配列」や「for文」、「if文」、
Pythonの基本構文が多く学べました。
人によっては丁寧過ぎたかもしれませんが、
今回で基本部分を大分説明できたので、
次回以降はペースアップしてお話していきます!
次回は「データ分析」編です!
今回取得してきたデータを使って、「ホームラン数」と関連性が高いデータを洗い出します!
※注意事項
WEBスクレイピングはWEBサイトにアクセスするため、
少なからずWEBサーバーに負担が掛かります。
大量データを取得したり、何度も実行したりしないようにしましょう!
※次の記事へ
-

-
Python機械学習「ホームラン数予測③」データ分析編!
ホームラン数を予測できるように機械学習させたいけど、 どんな情報を渡せば良いんだろう。。 片っ端から渡して色々と試せばいいんだろうか。。 こんにちは、古賀です!   ...
続きを見る



